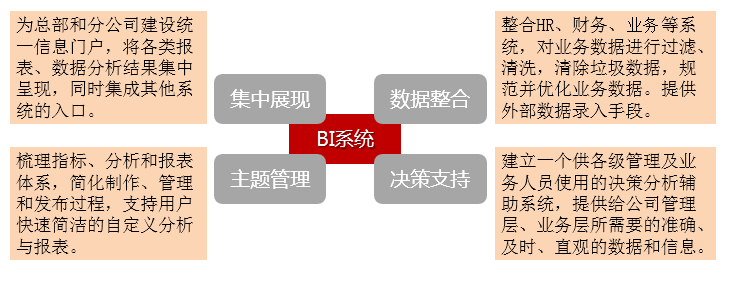
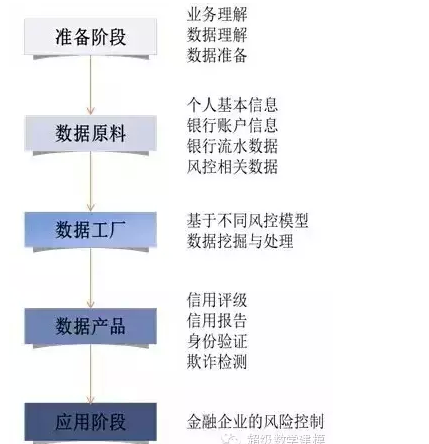
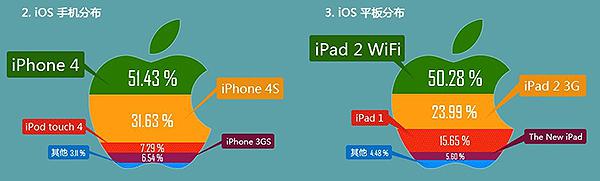
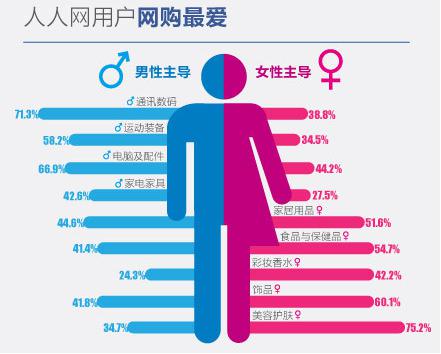
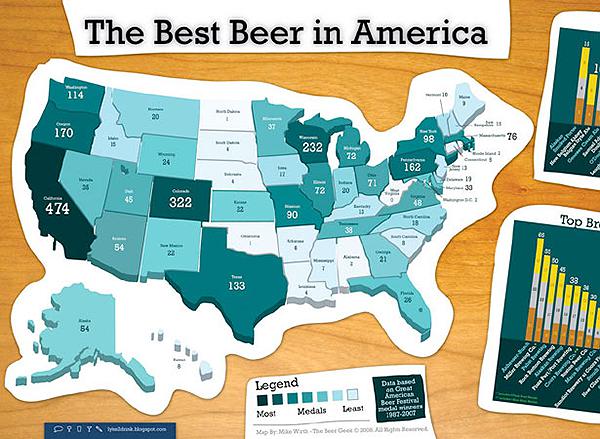
BI(商業智能)的部署應用成為2010年CIO關注的焦點。當前30%的成功率成為困擾BI前進的「絆腳石」,如果只是從企業部署應用的層度來講,目前企業只有首先理清了自身存在的因素,才能進一步的前進。作為CIO,無論是做什麼類型的系統,業務流程和業務資料都是非常重要的,做BI也是同樣的道理。如果拋開BI產品,從用戶的的角度出發,那麼在用戶做部署BI時,應該是先解決業務流程問題還是解決資料問題?近日,網友「olive」在 ITPUB論壇發起一場關於BI設計階段業務流程和業務資料重要程度的的探討引起了眾多BI實施者的關注。
情景還原:
網友olive指出:「公司內部一些跨部門的流程運行不太順暢,關鍵是各個部門各自為政,各用各的系統,各家自掃門前雪,而且信息對其他部門不透明,造成跨部門的資料查詢或協調比較困難。另外某些流程步驟依然採用古老的紙筆。針對這些問題老闆打算做一個通盤的改進,打通流程,然後上一個系統讓各相關部門都在上面運作,以提高總體效率。
和用戶討論這個問題,我們認為關鍵是要確定總的工作流程,然後依據流程確定資料和資料流。但是用戶認為關鍵是資料,只要把資料統統放進資料庫,什麼時候要用什麼時候拿出來,就是這麼簡單。
雙方各執己見。我們認為,資料要依附於流程才有意義,如果有些資料在任何流程中都沒有用到,那麼這些資料就是沒有用的。所以流程是關鍵,必須要先確定流程,然後再流程的每一步上確定輸入和輸出的資料,然後才能設計資料模型來存放資料。
但是用戶認為,不管有用沒用,把資料統統放在中心資料庫里,沒用就讓他放著,有用的時候拿出來,就可以解決一切問題。還舉了一個例子,說前段時間要做一個統計,需要 10年前的某些資料,但是這些資料當時沒有放在系統資料庫中,結果現在找不到了,統計也沒法做了。
所以即使是「沒用」的資料,也要放起來,誰知道以後有沒有用?只要有了資料,一切都好辦。所以資料是關鍵。」
網友「olive」個人認為,用戶的觀點顯然是有錯誤的,但是似乎又找不到有力的理據來說服他們。
圍繞BI的設計階段業務流程和業務資料哪個最重要的話題,筆者從論壇中了解到大量的專家、網友對於此進行了激烈的探討。筆者整理了這些專家、網友的聲音,結合在採訪已經實施或者關注BI的CIO,共同來分析解析BI設計階段「雞」和「蛋」的問題。
業務流程最重要
網友「ccwlm741212」指出,業務資料始終跟著業務流程走的,這是實施的問題。客戶固定自己的觀點,需要指導和疏通否則怎麼實施?
網友「123crm 」認為,這個問題無非就是一個系統分析的過程。按照面向對象的方式,先有業務模型,然後才有概念模型。你們公司的內部流程管理的問題,怎麼扯到用戶身上去了?流程是一個方面還涉及到業務模式的變革,流程變動,涉及一大堆人(每個流程環節的崗位職責變動)的考核變動。
不管有沒有IT系統,業務流程和業務實體都是客觀存在的。業務流程和業務模式是可以完全脫離IT系統的,要解決的問題是業務流程的梳理和對應的業務模式的變革。然後在IT系統中落地。依據系統分析的原則 在現在這個階段還是跟具體的實現扯不上太大的關係。
所謂的資料也好,其他的也好。只是用來支撐企業生產和業務運營,也可能包括一些非功能性的需求。
當然還得包括很多系統的非功能性需求。這個是本末倒置。底層的資料是流程梳理出來的一些抽象的實體。
網友「ccwlm741212」認為,如果按照用戶的想法做其實就是信息孤島,各自為政階段。
網友 「dawuwei1983」認為,流程比較重要,因為上系統畢竟是要改變現狀。先反覆確認流程,把流程確定。然後把業務資料套進去(肯定有特例,但說服甲方忍受,畢竟上workflow就是要規則化辦公流程啊,他們肯定接受)
網友「 近九成網友 」認為,用戶之間的資料是有聯繫的,這個聯繫就是業務流程。如果各自為陣,資料是有了但是資料之間的對應關係不存在,要一堆不能互相聯繫的資料幹什麼用?比如銷售認為A是個整體,而生產認為A是可以拆分的一堆東西,管理時也是按照一堆東西來管理的,那麼,按照他們說的資料是有了但是銷售和生產的資料無法聯繫起來,有用嗎?
網友「馬甲168 」指出,先整業務流程,業務流程整順了,再整資料不然你的業務流程朝令夕改,你的資料永遠都是垃圾。
業務流程和業務資料同樣重要
網友「123crm 」同時指出,如果不按照用戶的想法做,你能推動得了? 實際上,這些問題都不是IT解決的。配套的業務流程和業務模式的變革沒有跟上。IT系統在哪裡,也沒有人用。推動下來的流程,所有人的崗位職責和崗位流程都會發生變化,別人還是想在OA,或者直接回復郵件解決問題。需要強有力的自上而下的推動力才行。
網友「sead 」:用戶只想談資料迴避流程,期望資料入庫,流程依舊。避免權利重組。作為調研者,了解現有資料和業務流程即可,流程重組只要和大領導討論,不要和基層強辯。
網友「cowherd」: 如果不同業務資料全部都是用戶在一個地方,一次性錄入完成,可以想見錄入資料的質量。只有各自錄入自己負責的業務資料,才能保證各自錄入資料的準確性,而要保證各自錄入資料之間的關聯,那只能通過流程來控制,不能和基層具體辦事人員爭論系統全局問題。
不管怎樣如果在流程上扯皮,那還得回到資料上來,最後讓用戶明白,不按新的流程來根本不能保證資料的準確性,實現不了老闆的需求,扯什麼都是沒用的。
網友「olive「補充到,顯然用戶不想改動流程,只想得到更多的資料。但不講流程只講資料,只能是空中樓閣。
網友「 bq_wang 」認為,BI的目的是為了提供決策支持,不過是現有資料的報表BI是基於已有流程和資料分析,當然通過BI你可以反映出企業流程是否合理,是否需要改進;企業資料質量是否有問題等等。
網友「fals」認為,為什麼要把資料和流程對立起來?業務流程和業務資料本來就是統一的,是一個問題的兩個方面。
1 、原始資料(不是統計資料)是從哪裡來的?是怎麼產生的?
資料一定是從業務中產生的,一定是業務本身就具備的屬性。
2 、哪些資料先產生?哪些資料後產生?
一定是先發生業務的資料先產生,後發生業務的資料後產生。
3 、不同的資料與資料之間的相互關係由誰來定義?
一定是業務流程和業務關係來定義的!
使用部門是希望基礎資料全採集,後期才能提取使用,這個要求是完全合理的,我們不能預見今後會使用哪些資料,因此在業務發生的當時把業務屬性資料全部採集到資料庫中,實際上是完全可行的。
業務部門疑惑的問題是:每一個業務對象的需要定義哪些屬性?比如一個個人基本信息中,除了姓名性別外,是不是需要記錄他的手機號、家庭電話號碼、辦公室電話號碼、家庭住址、緊急聯繫人、緊急聯繫人電話、與緊急聯繫人的關係……這些資料才是需要與業務部門討論的。
業務部門希望這些資料盡量的全,但實際上是不可能的;今天的大多數系統記錄個人信息時也不記錄他們的email地址,但很快就會發現這是需要的,以後可能還會要求記錄QQ號什麼的,這些東西是我們沒法預測的,但是這東西隨時可以通過修改資料庫結構在需要的時候增加。
關係型資料庫設計來就是讓人能夠根據業務的擴展而不斷地增加新的信息的,所以疑慮完全可以讓業務部門打消掉。在系統早期設計的時候,完全可以不考慮得那麼全,在需要的時候再增加就行了。
很不理解做信息系統為什麼一定需要改動流程??按他們現有的業務流程,把手工的業務搬到信息系統里就不行了嗎?這是最簡單的辦法,為什麼一定要用戶改動流程?
改動業務流程一定是因為資料的原因:以前手工操作的時候為了某些原因方便之類的,增加了一些業務環節,現在信息系統上起來了,這些環節可以不要了。
管理也是為基礎業務和核心業務服務的,管理的目標是讓核心業務效率更高、資源配置更合理,而不是單純的為了領導的某些統計資料!!這個一定不能本末倒置!
網友「fals」指出同時建議,找專業的諮詢公司先拿出一個可行的解決方案。至少需要解決以下幾個問題:
1 、各部門之間在業務意義上相同的資料,在資料庫中存在著不同的編碼方式、組織方式,計算機難以自動判斷這些資料的業務意義是否相同。也就是說,必須解決各系統之間元資料定義的標準化問題,否則各部門的系統之間資料交換是一場空談。
2 、各部門之間的實際業務銜接是流暢的,但在全局的環境中信息流轉中不暢通,而且在整個大的流程中某些環節還是手工處理。因此樓主必須解決新的大系統與各部門原有業務系統的銜接問題,可以是全部替換——這個相信阻力會很大,特別是對於那些信息系統已經應用得比較好的部門;或者是做一個新系統,與各部門原有系統通過資料介面的方式進行資料交換和銜接——這樣的話,大系統會做得非常複雜。
3、對於現有個別業務環節還是手工的情況,只能在新系統中解決,這個相反是最好解決的。
因此,一個可行的做法是:建立一個全新的大系統,這個大系統跑全局的業務流程,主要解決部門與部門之間的業務銜接問題,涉及到各部門內部流程的,仍然使用各部門自有的系統來處理。
大系統監控各部門的業務系統中新產生的需要下一業務部門處理的資料,如A部門接了一個訂單,需要B部門評估成本,那麼大系統監測到A部門新增加了訂單時,就將訂單的相關資料轉換成B部門的信息系統能夠處理的資料寫入B部門的系統中。對於全局性的統計需求,可以將需要的資料——或者業務部門所說的「全部」資料統一轉換為標準資料之後提取到大系統的資料中心來,再按大老闆的統計要求進行二次加工。
這個方案的關鍵在於兩點:資料標準和系統介面。優勢在於對業務部門目前使用的系統儘可能少改或者不改,對各部門內部業務基本無干擾,即使是調整流程也僅僅是局部的調整,不會涉及各部門的利益。
至於各部門都需要使用的共同資料,也可以全面性的清理一下,由大系統從首次產生這些信息的部門系統里定期提取,再轉換後寫入各部門的系統中。
CIO解讀
據上海家化聯合股份有限公司信息管理部總監孫昊介紹,上海家化是是前年開始做BI的。對於BI的設計階段業務流程和業務資料哪個重要?孫昊指出,業務流程是資料正確性和及時性的保證,現在成為真正的資料倉庫但對於智能的要求,我們還在完善。
名企CIO解讀BI的博弈
上海家化聯合股份有限公司信息管理部總監孫昊認為,現在的BI應用很多公司還處於報表階段,做些交叉分析。孫昊認為,業務流程首先保證資料源的一致性,第二保證計算公式(KPI等)的統一性,第三保證系統處理的客觀性(自動化)。
而來自元洲裝飾董事長助理兼CIO白虹認為,BI的設計階段還是業務流程比較重要,流程決定了資料質量。
關於BI:
BI 商業智能也稱作BI是英文單詞Business Intelligence的縮寫。商業智能通常被理解為將企業中現有的資料轉化為知識,幫助企業做出明智的業務經營決策的工具。這裡所談的資料包括來自企業業務系統的訂單、庫存、交易賬目、客戶和供應商等來自企業所處行業和競爭對手的資料以及來自企業所處的其他外部環境中的各種資料。而商業智能能夠輔助的業務經營決策,既可以是操作層的,也可以是戰術層和戰略層的決策。為了將資料轉化為知識,需要利用資料倉庫、聯機分析處理(OLAP)工具和資料挖掘等技術。因此,從技術層面上講,商業智能不是什麼新技術,它只是資料倉庫、OLAP和資料挖掘等技術的綜合運用。
商業智能的概念最早在 1996年提出。當時將商業智能定義為一類由資料倉庫(或資料集市)、查詢報表、資料分析、資料挖掘、資料備份和恢復等部分組成的、以幫助企業決策為目的技術及其應用。目前,商業智能通常被理解為將企業中現有的資料轉化為知識,幫助企業做出明智的業務經營決策的工具。這裡所談的資料包括來自企業業務系統的訂單、庫存、交易賬目、客戶和供應商資料及來自企業所處行業和競爭對手的資料,以及來自企業所處的其他外部環境中的各種資料。而商業智能能夠輔助的業務經營決策既可以是操作層的,也可以是戰術層和戰略層的決策。為了將資料轉化為知識,需要利用資料倉庫、聯機分析處理(OLAP)工具和資料挖掘等技術。因此,從技術層面上講,商業智能不是什麼新技術,它只是資料倉庫、OLAP和資料挖掘等技術的綜合運用。
網友olive指出:「公司內部一些跨部門的流程運行不太順暢,關鍵是各個部門各自為政,各用各的系統,各家自掃門前雪,而且信息對其他部門不透明,造成跨部門的資料查詢或協調比較困難。另外某些流程步驟依然採用古老的紙筆。針對這些問題老闆打算做一個通盤的改進,打通流程,然後上一個系統讓各相關部門都在上面運作,以提高總體效率。
和用戶討論這個問題,我們認為關鍵是要確定總的工作流程,然後依據流程確定資料和資料流。但是用戶認為關鍵是資料,只要把資料統統放進資料庫,什麼時候要用什麼時候拿出來,就是這麼簡單。
雙方各執己見。我們認為,資料要依附於流程才有意義,如果有些資料在任何流程中都沒有用到,那麼這些資料就是沒有用的。所以流程是關鍵,必須要先確定流程,然後再流程的每一步上確定輸入和輸出的資料,然後才能設計資料模型來存放資料。
但是用戶認為,不管有用沒用,把資料統統放在中心資料庫里,沒用就讓他放著,有用的時候拿出來,就可以解決一切問題。還舉了一個例子,說前段時間要做一個統計,需要 10年前的某些資料,但是這些資料當時沒有放在系統資料庫中,結果現在找不到了,統計也沒法做了。
所以即使是「沒用」的資料,也要放起來,誰知道以後有沒有用?只要有了資料,一切都好辦。所以資料是關鍵。」
網友「olive」個人認為,用戶的觀點顯然是有錯誤的,但是似乎又找不到有力的理據來說服他們。
圍繞BI的設計階段業務流程和業務資料哪個最重要的話題,筆者從論壇中了解到大量的專家、網友對於此進行了激烈的探討。筆者整理了這些專家、網友的聲音,結合在採訪已經實施或者關注BI的CIO,共同來分析解析BI設計階段「雞」和「蛋」的問題。
業務流程最重要
網友「ccwlm741212」指出,業務資料始終跟著業務流程走的,這是實施的問題。客戶固定自己的觀點,需要指導和疏通否則怎麼實施?
網友「123crm 」認為,這個問題無非就是一個系統分析的過程。按照面向對象的方式,先有業務模型,然後才有概念模型。你們公司的內部流程管理的問題,怎麼扯到用戶身上去了?流程是一個方面還涉及到業務模式的變革,流程變動,涉及一大堆人(每個流程環節的崗位職責變動)的考核變動。
不管有沒有IT系統,業務流程和業務實體都是客觀存在的。業務流程和業務模式是可以完全脫離IT系統的,要解決的問題是業務流程的梳理和對應的業務模式的變革。然後在IT系統中落地。依據系統分析的原則 在現在這個階段還是跟具體的實現扯不上太大的關係。
所謂的資料也好,其他的也好。只是用來支撐企業生產和業務運營,也可能包括一些非功能性的需求。
當然還得包括很多系統的非功能性需求。這個是本末倒置。底層的資料是流程梳理出來的一些抽象的實體。
網友「ccwlm741212」認為,如果按照用戶的想法做其實就是信息孤島,各自為政階段。
網友 「dawuwei1983」認為,流程比較重要,因為上系統畢竟是要改變現狀。先反覆確認流程,把流程確定。然後把業務資料套進去(肯定有特例,但說服甲方忍受,畢竟上workflow就是要規則化辦公流程啊,他們肯定接受)
網友「 近九成網友 」認為,用戶之間的資料是有聯繫的,這個聯繫就是業務流程。如果各自為陣,資料是有了但是資料之間的對應關係不存在,要一堆不能互相聯繫的資料幹什麼用?比如銷售認為A是個整體,而生產認為A是可以拆分的一堆東西,管理時也是按照一堆東西來管理的,那麼,按照他們說的資料是有了但是銷售和生產的資料無法聯繫起來,有用嗎?
網友「馬甲168 」指出,先整業務流程,業務流程整順了,再整資料不然你的業務流程朝令夕改,你的資料永遠都是垃圾。
業務流程和業務資料同樣重要
網友「123crm 」同時指出,如果不按照用戶的想法做,你能推動得了? 實際上,這些問題都不是IT解決的。配套的業務流程和業務模式的變革沒有跟上。IT系統在哪裡,也沒有人用。推動下來的流程,所有人的崗位職責和崗位流程都會發生變化,別人還是想在OA,或者直接回復郵件解決問題。需要強有力的自上而下的推動力才行。
網友「sead 」:用戶只想談資料迴避流程,期望資料入庫,流程依舊。避免權利重組。作為調研者,了解現有資料和業務流程即可,流程重組只要和大領導討論,不要和基層強辯。
網友「cowherd」: 如果不同業務資料全部都是用戶在一個地方,一次性錄入完成,可以想見錄入資料的質量。只有各自錄入自己負責的業務資料,才能保證各自錄入資料的準確性,而要保證各自錄入資料之間的關聯,那只能通過流程來控制,不能和基層具體辦事人員爭論系統全局問題。
不管怎樣如果在流程上扯皮,那還得回到資料上來,最後讓用戶明白,不按新的流程來根本不能保證資料的準確性,實現不了老闆的需求,扯什麼都是沒用的。
網友「olive「補充到,顯然用戶不想改動流程,只想得到更多的資料。但不講流程只講資料,只能是空中樓閣。
網友「 bq_wang 」認為,BI的目的是為了提供決策支持,不過是現有資料的報表BI是基於已有流程和資料分析,當然通過BI你可以反映出企業流程是否合理,是否需要改進;企業資料質量是否有問題等等。
網友「fals」認為,為什麼要把資料和流程對立起來?業務流程和業務資料本來就是統一的,是一個問題的兩個方面。
1 、原始資料(不是統計資料)是從哪裡來的?是怎麼產生的?
資料一定是從業務中產生的,一定是業務本身就具備的屬性。
2 、哪些資料先產生?哪些資料後產生?
一定是先發生業務的資料先產生,後發生業務的資料後產生。
3 、不同的資料與資料之間的相互關係由誰來定義?
一定是業務流程和業務關係來定義的!
使用部門是希望基礎資料全採集,後期才能提取使用,這個要求是完全合理的,我們不能預見今後會使用哪些資料,因此在業務發生的當時把業務屬性資料全部採集到資料庫中,實際上是完全可行的。
業務部門疑惑的問題是:每一個業務對象的需要定義哪些屬性?比如一個個人基本信息中,除了姓名性別外,是不是需要記錄他的手機號、家庭電話號碼、辦公室電話號碼、家庭住址、緊急聯繫人、緊急聯繫人電話、與緊急聯繫人的關係……這些資料才是需要與業務部門討論的。
業務部門希望這些資料盡量的全,但實際上是不可能的;今天的大多數系統記錄個人信息時也不記錄他們的email地址,但很快就會發現這是需要的,以後可能還會要求記錄QQ號什麼的,這些東西是我們沒法預測的,但是這東西隨時可以通過修改資料庫結構在需要的時候增加。
關係型資料庫設計來就是讓人能夠根據業務的擴展而不斷地增加新的信息的,所以疑慮完全可以讓業務部門打消掉。在系統早期設計的時候,完全可以不考慮得那麼全,在需要的時候再增加就行了。
很不理解做信息系統為什麼一定需要改動流程??按他們現有的業務流程,把手工的業務搬到信息系統里就不行了嗎?這是最簡單的辦法,為什麼一定要用戶改動流程?
改動業務流程一定是因為資料的原因:以前手工操作的時候為了某些原因方便之類的,增加了一些業務環節,現在信息系統上起來了,這些環節可以不要了。
管理也是為基礎業務和核心業務服務的,管理的目標是讓核心業務效率更高、資源配置更合理,而不是單純的為了領導的某些統計資料!!這個一定不能本末倒置!
網友「fals」指出同時建議,找專業的諮詢公司先拿出一個可行的解決方案。至少需要解決以下幾個問題:
1 、各部門之間在業務意義上相同的資料,在資料庫中存在著不同的編碼方式、組織方式,計算機難以自動判斷這些資料的業務意義是否相同。也就是說,必須解決各系統之間元資料定義的標準化問題,否則各部門的系統之間資料交換是一場空談。
2 、各部門之間的實際業務銜接是流暢的,但在全局的環境中信息流轉中不暢通,而且在整個大的流程中某些環節還是手工處理。因此樓主必須解決新的大系統與各部門原有業務系統的銜接問題,可以是全部替換——這個相信阻力會很大,特別是對於那些信息系統已經應用得比較好的部門;或者是做一個新系統,與各部門原有系統通過資料介面的方式進行資料交換和銜接——這樣的話,大系統會做得非常複雜。
3、對於現有個別業務環節還是手工的情況,只能在新系統中解決,這個相反是最好解決的。
因此,一個可行的做法是:建立一個全新的大系統,這個大系統跑全局的業務流程,主要解決部門與部門之間的業務銜接問題,涉及到各部門內部流程的,仍然使用各部門自有的系統來處理。
大系統監控各部門的業務系統中新產生的需要下一業務部門處理的資料,如A部門接了一個訂單,需要B部門評估成本,那麼大系統監測到A部門新增加了訂單時,就將訂單的相關資料轉換成B部門的信息系統能夠處理的資料寫入B部門的系統中。對於全局性的統計需求,可以將需要的資料——或者業務部門所說的「全部」資料統一轉換為標準資料之後提取到大系統的資料中心來,再按大老闆的統計要求進行二次加工。
這個方案的關鍵在於兩點:資料標準和系統介面。優勢在於對業務部門目前使用的系統儘可能少改或者不改,對各部門內部業務基本無干擾,即使是調整流程也僅僅是局部的調整,不會涉及各部門的利益。
至於各部門都需要使用的共同資料,也可以全面性的清理一下,由大系統從首次產生這些信息的部門系統里定期提取,再轉換後寫入各部門的系統中。
CIO解讀
據上海家化聯合股份有限公司信息管理部總監孫昊介紹,上海家化是是前年開始做BI的。對於BI的設計階段業務流程和業務資料哪個重要?孫昊指出,業務流程是資料正確性和及時性的保證,現在成為真正的資料倉庫但對於智能的要求,我們還在完善。
名企CIO解讀BI的博弈
上海家化聯合股份有限公司信息管理部總監孫昊認為,現在的BI應用很多公司還處於報表階段,做些交叉分析。孫昊認為,業務流程首先保證資料源的一致性,第二保證計算公式(KPI等)的統一性,第三保證系統處理的客觀性(自動化)。
而來自元洲裝飾董事長助理兼CIO白虹認為,BI的設計階段還是業務流程比較重要,流程決定了資料質量。
關於BI:
BI 商業智能也稱作BI是英文單詞Business Intelligence的縮寫。商業智能通常被理解為將企業中現有的資料轉化為知識,幫助企業做出明智的業務經營決策的工具。這裡所談的資料包括來自企業業務系統的訂單、庫存、交易賬目、客戶和供應商等來自企業所處行業和競爭對手的資料以及來自企業所處的其他外部環境中的各種資料。而商業智能能夠輔助的業務經營決策,既可以是操作層的,也可以是戰術層和戰略層的決策。為了將資料轉化為知識,需要利用資料倉庫、聯機分析處理(OLAP)工具和資料挖掘等技術。因此,從技術層面上講,商業智能不是什麼新技術,它只是資料倉庫、OLAP和資料挖掘等技術的綜合運用。
商業智能的概念最早在 1996年提出。當時將商業智能定義為一類由資料倉庫(或資料集市)、查詢報表、資料分析、資料挖掘、資料備份和恢復等部分組成的、以幫助企業決策為目的技術及其應用。目前,商業智能通常被理解為將企業中現有的資料轉化為知識,幫助企業做出明智的業務經營決策的工具。這裡所談的資料包括來自企業業務系統的訂單、庫存、交易賬目、客戶和供應商資料及來自企業所處行業和競爭對手的資料,以及來自企業所處的其他外部環境中的各種資料。而商業智能能夠輔助的業務經營決策既可以是操作層的,也可以是戰術層和戰略層的決策。為了將資料轉化為知識,需要利用資料倉庫、聯機分析處理(OLAP)工具和資料挖掘等技術。因此,從技術層面上講,商業智能不是什麼新技術,它只是資料倉庫、OLAP和資料挖掘等技術的綜合運用。