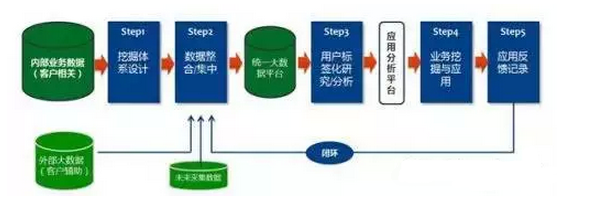
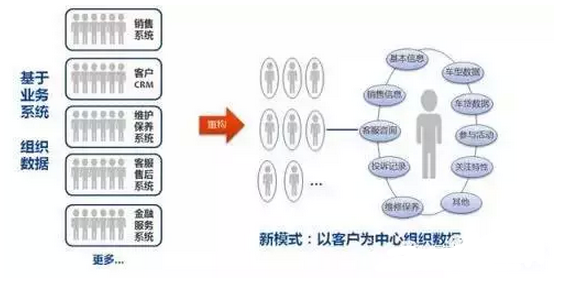
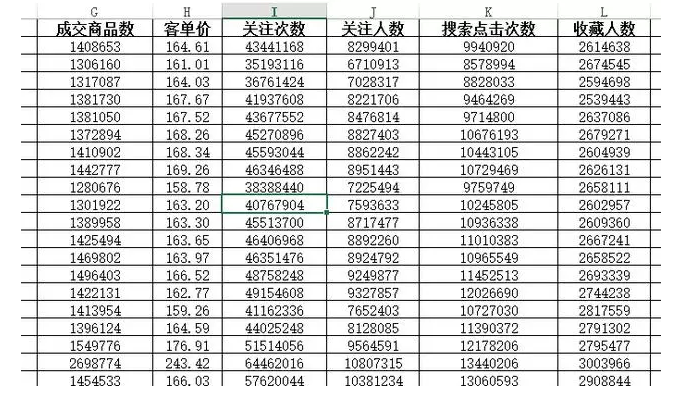
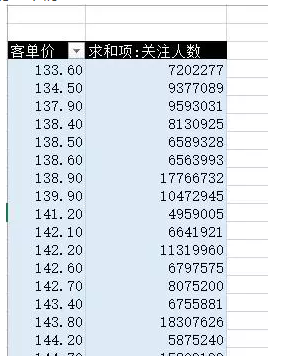
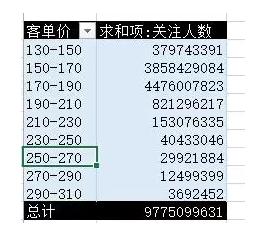
【引子】
Porterfield的最新創業項目是Looker,一個商業資料分析解決方案提供商。主人公在下面這篇文章中向我們講解創業者們如何可以從一開始就設計好資料分析的基本框架:將資料儲存於何處?用什麼工具分析最好?可以規避哪些常見的錯誤?以及,今天的你如何亡羊補牢?
關於資料分析,避免6個錯誤
1. 走得太快,沒空回頭看路
初創公司里的人們彷彿一直在被人念著緊箍咒:「要麼快要麼死,要麼快要麼死。」他們是如此著急於產品開發,以至於他們常常沒有空想用戶對產品的具體使用細節,產品在哪些場景怎麼被使用,產品的哪些部分被使用,以及用戶回頭二次使用產品的原因主要有哪些。而這些問題如果沒有資料難以回答。
2.你沒有記錄足夠的資料
光給你的團隊看呈現總結出來的資料是沒有用的。如果沒有精確到日乃至小時的變化明細,你無法分析出來資料變化背後看不見的手。如果只是粗放的,斷續的統計,沒有人可以解讀出各種細微因素對於銷售或者用戶使用習慣的影響。
與此同時,資料儲存越來越便宜。同時做大量的分析也不是什麼高風險的事情,只要買足夠的空間就不會有system breakdown的風險。因此,記錄儘可能多的資料總不會是一件壞事。
不要害怕量大。對於初創企業來說,巨量資料其實還是比較少見的事情。如果正處於初創期的你果真(幸運地)有這樣的困擾,Porterfield(本文)推薦使用一個叫Hadoop的平台。
3. 其實你的團隊成員常常感覺自己在盲人摸象
許多公司以為他們把資料扔給Mixpanel, Kissmetrics,或者Google Analytics就夠了,但他們常常忽略了團隊的哪些成員能真正解讀這些資料的內在含義。你需要經常提醒團隊裡面每一位成員多去理解這些資料,並更多地基於資料來做決策。要不然,你的產品團隊只會盲目地開發產品,並祈禱能踩中熱點,不管最終成功還是失敗了都是一頭霧水。
舉例:
有天你決定採用市場上常見的病毒營銷手段吸引新用戶。如你所願,用戶量啪啪啪地上來了。可此時你會遇到新的迷茫:你無法衡量這個營銷手段對老用戶的影響。人們可能被吸引眼球,註冊為新用戶,然後厭倦而不再使用。你可能為吸引了一幫沒有價值的用戶付出了過高的代價。而你的產品團隊可能還在沾沾自喜,認為這個損害產品的營銷手段是成功的。
這種傻錯誤經常發生。而如果你的企業在一開始就建立起人人可自助使用的資料平台,來解答他們工作中最重要的疑惑,則可以避免上文所說的悲劇。
4. 把資料存放在不合適的地方
先讓我們來看一個正確示範吧。Porerfield提到他有個客戶整合了NoSQL, Redshift,Kitnesis以及Looker的資源自創了一個資料分析框架。這個框架不僅能在很高的量級上捕獲及儲存自己的資料,還能承受每月數以百萬計的點擊流量,還能讓所有人查詢自己想要的資料。這個系統甚至可以讓不懂SQL語言的小白用戶們真正理解資料的意義。而在資料分析的世界裡,基本上如果你不會SQL, 你就完蛋了。如果總是要等待工程師去把資料跑出來,那就是把自己陷入困境。而工程師在不理解需求的情況下建立的演算法或者買的軟體對於使用者來說往往是個煎熬,因為他們對資料的使用往往與前者不再同一水平線上。
你需要讓你所有的資料都存放在同一個地方。這個是關鍵關鍵最關鍵的原則。
Porterfield的最新創業項目是Looker,一個商業資料分析解決方案提供商。主人公在下面這篇文章中向我們講解創業者們如何可以從一開始就設計好資料分析的基本框架:將資料儲存於何處?用什麼工具分析最好?可以規避哪些常見的錯誤?以及,今天的你如何亡羊補牢?
關於資料分析,避免6個錯誤
1. 走得太快,沒空回頭看路
初創公司里的人們彷彿一直在被人念著緊箍咒:「要麼快要麼死,要麼快要麼死。」他們是如此著急於產品開發,以至於他們常常沒有空想用戶對產品的具體使用細節,產品在哪些場景怎麼被使用,產品的哪些部分被使用,以及用戶回頭二次使用產品的原因主要有哪些。而這些問題如果沒有資料難以回答。
2.你沒有記錄足夠的資料
光給你的團隊看呈現總結出來的資料是沒有用的。如果沒有精確到日乃至小時的變化明細,你無法分析出來資料變化背後看不見的手。如果只是粗放的,斷續的統計,沒有人可以解讀出各種細微因素對於銷售或者用戶使用習慣的影響。
與此同時,資料儲存越來越便宜。同時做大量的分析也不是什麼高風險的事情,只要買足夠的空間就不會有system breakdown的風險。因此,記錄儘可能多的資料總不會是一件壞事。
不要害怕量大。對於初創企業來說,巨量資料其實還是比較少見的事情。如果正處於初創期的你果真(幸運地)有這樣的困擾,Porterfield(本文)推薦使用一個叫Hadoop的平台。
3. 其實你的團隊成員常常感覺自己在盲人摸象
許多公司以為他們把資料扔給Mixpanel, Kissmetrics,或者Google Analytics就夠了,但他們常常忽略了團隊的哪些成員能真正解讀這些資料的內在含義。你需要經常提醒團隊裡面每一位成員多去理解這些資料,並更多地基於資料來做決策。要不然,你的產品團隊只會盲目地開發產品,並祈禱能踩中熱點,不管最終成功還是失敗了都是一頭霧水。
舉例:
有天你決定採用市場上常見的病毒營銷手段吸引新用戶。如你所願,用戶量啪啪啪地上來了。可此時你會遇到新的迷茫:你無法衡量這個營銷手段對老用戶的影響。人們可能被吸引眼球,註冊為新用戶,然後厭倦而不再使用。你可能為吸引了一幫沒有價值的用戶付出了過高的代價。而你的產品團隊可能還在沾沾自喜,認為這個損害產品的營銷手段是成功的。
這種傻錯誤經常發生。而如果你的企業在一開始就建立起人人可自助使用的資料平台,來解答他們工作中最重要的疑惑,則可以避免上文所說的悲劇。
4. 把資料存放在不合適的地方
先讓我們來看一個正確示範吧。Porerfield提到他有個客戶整合了NoSQL, Redshift,Kitnesis以及Looker的資源自創了一個資料分析框架。這個框架不僅能在很高的量級上捕獲及儲存自己的資料,還能承受每月數以百萬計的點擊流量,還能讓所有人查詢自己想要的資料。這個系統甚至可以讓不懂SQL語言的小白用戶們真正理解資料的意義。而在資料分析的世界裡,基本上如果你不會SQL, 你就完蛋了。如果總是要等待工程師去把資料跑出來,那就是把自己陷入困境。而工程師在不理解需求的情況下建立的演算法或者買的軟體對於使用者來說往往是個煎熬,因為他們對資料的使用往往與前者不再同一水平線上。
你需要讓你所有的資料都存放在同一個地方。這個是關鍵關鍵最關鍵的原則。
讓我們回到前文那個假設存在的公司。他們做了一個又一個病毒營銷,但是沒有把用戶活動資料放在同一框架內,所以他們無法分析一個活動是如何關聯到另一個活動的。他們也無法進行一個橫跨日常運營以及活動期間的資料分析比較。
很多公司把資料發給外包商儲存,然後就當甩手掌柜了。可是常常這些資料到了外包商手裡就會變成其他形式,而轉化回來則需要不少工序。這些資料往往是某些宣傳造勢活動時期你的網站或者產品的相關資料。結合日常運營資料來看,你可以挖掘哪些活動促成了用戶轉化。而這樣結合日常運營資料來分析用戶使用歷程的方式是至關重要的。但令人震驚的是,儘管任何時期的所有運營資料都至關重要,許多公司仍不屑於捕獲及記錄他們。約一半以上Porterfield所見過的公司都將日常運營資料與活動資料分開來看。這樣嚴重妨礙了公司正確地理解與決策。
5. 目光短淺
任何一個好的資料分析框架在設計之初都必須滿足長期使用的需要。誠然,你總是可以調整你的框架。但資料積累越多,做調整的代價越大。而且常常做出調整後,你需要同時記錄新舊兩套系統來確保資料不會丟失。
因此,我們最好能在第一天就把框架設計好。其中一個簡單粗暴有效地方法就是所有能獲取的資料放在同一個可延展的平台。不需要浪費時間選擇一個最優解決方法,只要確認這個平台可以裝得下所有將來可能用到的資料,且跨平台也能跑起來就行了。一般來說這樣的原始平台能至少支撐一到兩年。
6. 過度總結
雖然說這個問題對於擁有巨量資料分析團隊的公司來說更常見,初創公司最好也能注意避免掉。試想一下,有多少公司只是記錄平均每分鐘多少銷售額,而不是具體每一分鐘銷售了多少金額?在過去由於運算能力有限,我們只能把海量資料總結成幾個點來看。但在當下,這些運算量根本不是問題,所有人都可以把運營資料精確到分鐘來記錄。而這些精確的記錄可以告訴你海量的信息,比如為什麼轉化率在上升或者下降。
人們常常自我陶醉於做出了幾張漂亮的圖標或者PPT。這些總結性的表達看上去很令人振奮,但我們不應該基於這些膚淺的總結來做決策,因為這些漂亮的總結性陳述並不能真正反映問題的實質。相反,我們更應該關注極端值(Outliers)。
3個簡單防護措施,幫你少走彎路
少犯錯誤遠比你想的重要,因為錯誤一旦發生,很容易耗費大量的工程時間和資源來彌補錯誤。如果不小心,你的工程師們可能花費昂貴的時間來為銷售團隊解碼資料,可能錯過無數寶貴的營銷機會。每當資料變得難使用或者理解時,你的團隊決策速度會變慢,因此你的生意進展必將受到拖累
好消息是,如果你從有用戶伊始就採用以下3個簡單的防護措施,你一定可以避免走很多彎路。
1. 任命一個商業資料首席工程師
如果你能在團隊中找到一個隊資料分析真正有興趣的工程師,你可以讓他負責記錄管理所有資料。這將為整個團隊節省海量的時間。Porterfield 分享到,在Looker, 這樣的一個商業資料首席工程師負責寫能記錄所有資料的腳本,從而方便大家總是能在同一個資料庫內獲取需要的信息。事實證明,這是個簡單有效的方法,極大地提高了團隊的工作效率。
2. 把資料放在開放的平台上
Porterfield強力推薦大家使用類似於Snowplow的開源平台,以能實時記錄所有與產品相關的活動事件資料。它使用方便,有好的技術支援,可以放量使用。而最棒的一點,它能與你其餘的資料框架很好的兼容。
3. 儘快將你的資料遷移到AWS Redshift或者其它大規模並行處理資料庫(MPP)上
對於還處於早期的公司來說,類似於Redshift這種基於雲端的MPP經常就是最好的選擇。因為他們價格便宜,便於部署和管理,並且擴展性強。在理想狀況下,你會希望從公司有記錄之初就將你的事件與操作的資料寫入亞馬遜Redshift之中。「使用Redshift的好處在於這個平台便宜,迅速,可訪問性高,」Porterfield說。並且,對於那些已經使用AWS服務的人來說,它(使用redshift)可以無縫接入你已有的架構中。你可以很容易的建設一個資料通道把資料直接傳入這個系統中進行分析處理。「Redshift能讓你靈活的寫入巨量的顆粒狀的資料而並不根據事件觸發量的多少這樣難以估計的參數來收費,」他說。「其它的服務會根據你儲存事件的多少來收費,所以當越來越多的人使用你的產品時,越來越多的操作資料會被記錄下來,這會導致最終的收費像火箭一樣越升越高。」
如何用資料分析佔領市場先機?
資料分析的價值取決於它能如何幫助你佔領市場先機。作為初創公司,所有的資料應該被用於你對公司不同階段設立的目標上。
舉例
一個快遞公司通常會檢測平均送達每件貨物的時間。這看上去是很關鍵的資料,但如果沒有充分的上下文(畢竟收貨人可能在一個街區外,也可能在幾百公里外),這也是沒有意義的。另一個角度上,平均送貨時間也沒有收貨人的整體滿意度重要。因此,你必須確保你的分析囊括了正確的資料。
請列舉量化你需要的結果:你希望你的客戶體驗是怎麼樣的?一些常見的成功資料分析會基於銷售或用戶轉化率(即如果客戶做了叉叉事情以後會購買或者成為用戶),轉化需要的時間,以及讓客戶產生負面體驗的比例。你會希望第一個比例很高,而後兩者降低。
通常來說,媒體網站會全然以網頁瀏覽量論英雄。但現在他們也開始注意一個叫做「注意力停留時長」的指標:人們在某個頁面專註多長時間,是否注意到某些字句,是否在上下拖動頁面,是否有看視頻,等等。他們不僅僅實在看用戶在某個頁面停留了多少時間,他們更需要知道用戶被頁面中的哪些部分吸引,且積極專註地瀏覽了多少時間。這樣可以幫助媒體網站設計新的標題,頁面設計和內容選擇,以延長這樣的注意力停留時長。這樣,他們可以革新網站設計的方式,來更好地打動他們的受眾。
另一個重點是監測留存用戶。成功的資料分析可以同時涵蓋日常運營資料以及活動資料,並橫向分析。如果你僅僅看日常運營資料,你能知道哪些人會回訪你的網站,哪些人可以達成復購。但你還需了解哪些回訪網站卻沒有復購的人群: 為什麼他們不願意再次購買?這樣的問題可以通過介乎運營與活動資料分析來找到答案。活動資料會告訴你哪些沒有購買行為的客戶按照何種順序瀏覽網站,注意到了什麼,點擊了什麼,在離開網站前做了什麼。當你跟蹤這個線路,你可以了解如何修改這種行為,來增加他們下次訪問時購買的可能性。
為了設計最適合你的資料籃子,你可以參考以下三個建議:
1. 尋找一類合適的用戶行為;
2. 測算多少比例的受眾會有這一類的用戶行為;
3. 測試這一類用戶行為是不是包含了重要的信息。
有時候,發明一個新的資料記錄籃子可以促成對公司很大的改變。
舉例
拿Venmo(翻譯君註:一個紐約的小額支付平台)舉個栗子吧。有段時間,公司的支付APP團隊聽說很多本想向朋友索取款項的用戶不慎把錢反而支付給了朋友,因為「索取款項」和「支付款項」的按鈕放在一塊很容易按錯。然而公司並不知道這個問題有多普遍,是否值得公司重新設計用戶界面。為了更好地做決策,他們設計了一個新的資料系統來檢測這個索取/支付失誤有多常見。他們把「A向B付款後不久B雙倍將款項付給了A」這種奇怪的支付行為全都找了出來。結果顯示,這個情況經常發生。所以在下次的產品更新中,他們修復了這個問題。
讓你的資料可分享
阻礙團隊輕鬆分享資料的罪魁禍首常常是資料的定義。因此,從一開始你最好充分完整地定義你的資料。可以考慮建立一個中央辭彙表wiki page, 來讓每個成員更容易理解。Porterfield指出,人們喜歡用奇怪的詞語給資料命名。比如「Ratio」這個詞就常備濫用,因為他們命名時常沒有把分子分母講清楚。
資料是大部分成功公司的生命線。好的資料分享不僅能增加公司的透明度,還能加強不同部門之間的協作。比如在很多公司里,不同部門常常會各自找工程師生成不同資料來回答同一問題。而如果有一個好的分享資料平台這樣的浪費時間精力可以被避免。
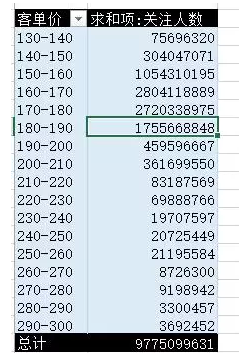
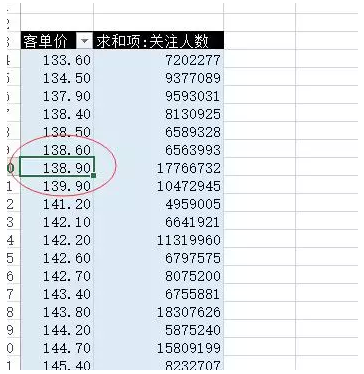
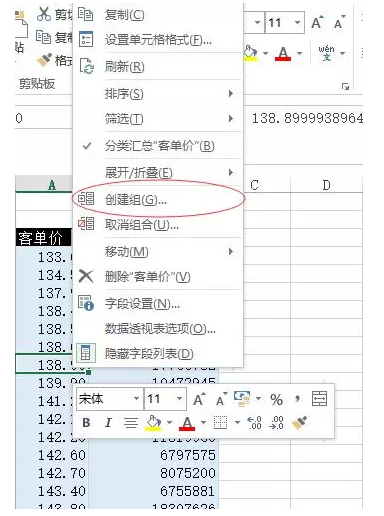
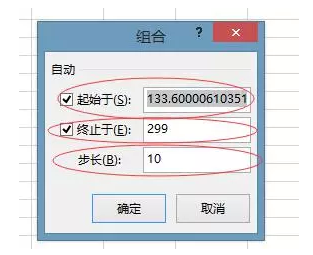
另外,讓資料形象化也是一個好平台能輕易做到的。把顆粒資料形象化為圖表可以讓團隊的每一個成員更好地解讀這些資料。對於大部分人來說,理解圖表比理解表格容易得多,因此把資料形象化可以幫助交流更加順暢。
不好的資料分析框架只會打擊人們的自信心。它會無形地把公司分為兩個派別:懂資料的大神以及不懂資料的白痴。這是個很常見的危險錯誤。你必須讓公司最小白的資料用戶都能輕鬆地生成自己需要的圖表並理解它。這是選擇資料平台的一個基本原則。
Poterfield總結道:好的資料分析能讓人們更有準備地去開會,幫銷售團隊問出更到位的問題,免去了無謂的猜測。人們不用再猜測他們的用戶在尋找什麼,或者為什麼他們達成銷售,或者為什麼他們不再回頭。人們也不用再猜測其他團隊的同事知道或者不知道什麼。而這一切都要歸功於從一開始就把資料框架設計好。
4500+企業選擇FineReport報表與 BI 商業智慧工具【免費下載】
opensource開發,類excel設計,全方位異質資料庫整合,資料填報、Flash列印、權限控制、行动應用、客制化、交互分析、報表協同作業管理系統。
分享自:資料觀
很多公司把資料發給外包商儲存,然後就當甩手掌柜了。可是常常這些資料到了外包商手裡就會變成其他形式,而轉化回來則需要不少工序。這些資料往往是某些宣傳造勢活動時期你的網站或者產品的相關資料。結合日常運營資料來看,你可以挖掘哪些活動促成了用戶轉化。而這樣結合日常運營資料來分析用戶使用歷程的方式是至關重要的。但令人震驚的是,儘管任何時期的所有運營資料都至關重要,許多公司仍不屑於捕獲及記錄他們。約一半以上Porterfield所見過的公司都將日常運營資料與活動資料分開來看。這樣嚴重妨礙了公司正確地理解與決策。
5. 目光短淺
任何一個好的資料分析框架在設計之初都必須滿足長期使用的需要。誠然,你總是可以調整你的框架。但資料積累越多,做調整的代價越大。而且常常做出調整後,你需要同時記錄新舊兩套系統來確保資料不會丟失。
因此,我們最好能在第一天就把框架設計好。其中一個簡單粗暴有效地方法就是所有能獲取的資料放在同一個可延展的平台。不需要浪費時間選擇一個最優解決方法,只要確認這個平台可以裝得下所有將來可能用到的資料,且跨平台也能跑起來就行了。一般來說這樣的原始平台能至少支撐一到兩年。
6. 過度總結
雖然說這個問題對於擁有巨量資料分析團隊的公司來說更常見,初創公司最好也能注意避免掉。試想一下,有多少公司只是記錄平均每分鐘多少銷售額,而不是具體每一分鐘銷售了多少金額?在過去由於運算能力有限,我們只能把海量資料總結成幾個點來看。但在當下,這些運算量根本不是問題,所有人都可以把運營資料精確到分鐘來記錄。而這些精確的記錄可以告訴你海量的信息,比如為什麼轉化率在上升或者下降。
人們常常自我陶醉於做出了幾張漂亮的圖標或者PPT。這些總結性的表達看上去很令人振奮,但我們不應該基於這些膚淺的總結來做決策,因為這些漂亮的總結性陳述並不能真正反映問題的實質。相反,我們更應該關注極端值(Outliers)。
3個簡單防護措施,幫你少走彎路
少犯錯誤遠比你想的重要,因為錯誤一旦發生,很容易耗費大量的工程時間和資源來彌補錯誤。如果不小心,你的工程師們可能花費昂貴的時間來為銷售團隊解碼資料,可能錯過無數寶貴的營銷機會。每當資料變得難使用或者理解時,你的團隊決策速度會變慢,因此你的生意進展必將受到拖累
好消息是,如果你從有用戶伊始就採用以下3個簡單的防護措施,你一定可以避免走很多彎路。
1. 任命一個商業資料首席工程師
如果你能在團隊中找到一個隊資料分析真正有興趣的工程師,你可以讓他負責記錄管理所有資料。這將為整個團隊節省海量的時間。Porterfield 分享到,在Looker, 這樣的一個商業資料首席工程師負責寫能記錄所有資料的腳本,從而方便大家總是能在同一個資料庫內獲取需要的信息。事實證明,這是個簡單有效的方法,極大地提高了團隊的工作效率。
2. 把資料放在開放的平台上
Porterfield強力推薦大家使用類似於Snowplow的開源平台,以能實時記錄所有與產品相關的活動事件資料。它使用方便,有好的技術支援,可以放量使用。而最棒的一點,它能與你其餘的資料框架很好的兼容。
3. 儘快將你的資料遷移到AWS Redshift或者其它大規模並行處理資料庫(MPP)上
對於還處於早期的公司來說,類似於Redshift這種基於雲端的MPP經常就是最好的選擇。因為他們價格便宜,便於部署和管理,並且擴展性強。在理想狀況下,你會希望從公司有記錄之初就將你的事件與操作的資料寫入亞馬遜Redshift之中。「使用Redshift的好處在於這個平台便宜,迅速,可訪問性高,」Porterfield說。並且,對於那些已經使用AWS服務的人來說,它(使用redshift)可以無縫接入你已有的架構中。你可以很容易的建設一個資料通道把資料直接傳入這個系統中進行分析處理。「Redshift能讓你靈活的寫入巨量的顆粒狀的資料而並不根據事件觸發量的多少這樣難以估計的參數來收費,」他說。「其它的服務會根據你儲存事件的多少來收費,所以當越來越多的人使用你的產品時,越來越多的操作資料會被記錄下來,這會導致最終的收費像火箭一樣越升越高。」
如何用資料分析佔領市場先機?
資料分析的價值取決於它能如何幫助你佔領市場先機。作為初創公司,所有的資料應該被用於你對公司不同階段設立的目標上。
舉例
一個快遞公司通常會檢測平均送達每件貨物的時間。這看上去是很關鍵的資料,但如果沒有充分的上下文(畢竟收貨人可能在一個街區外,也可能在幾百公里外),這也是沒有意義的。另一個角度上,平均送貨時間也沒有收貨人的整體滿意度重要。因此,你必須確保你的分析囊括了正確的資料。
請列舉量化你需要的結果:你希望你的客戶體驗是怎麼樣的?一些常見的成功資料分析會基於銷售或用戶轉化率(即如果客戶做了叉叉事情以後會購買或者成為用戶),轉化需要的時間,以及讓客戶產生負面體驗的比例。你會希望第一個比例很高,而後兩者降低。
通常來說,媒體網站會全然以網頁瀏覽量論英雄。但現在他們也開始注意一個叫做「注意力停留時長」的指標:人們在某個頁面專註多長時間,是否注意到某些字句,是否在上下拖動頁面,是否有看視頻,等等。他們不僅僅實在看用戶在某個頁面停留了多少時間,他們更需要知道用戶被頁面中的哪些部分吸引,且積極專註地瀏覽了多少時間。這樣可以幫助媒體網站設計新的標題,頁面設計和內容選擇,以延長這樣的注意力停留時長。這樣,他們可以革新網站設計的方式,來更好地打動他們的受眾。
另一個重點是監測留存用戶。成功的資料分析可以同時涵蓋日常運營資料以及活動資料,並橫向分析。如果你僅僅看日常運營資料,你能知道哪些人會回訪你的網站,哪些人可以達成復購。但你還需了解哪些回訪網站卻沒有復購的人群: 為什麼他們不願意再次購買?這樣的問題可以通過介乎運營與活動資料分析來找到答案。活動資料會告訴你哪些沒有購買行為的客戶按照何種順序瀏覽網站,注意到了什麼,點擊了什麼,在離開網站前做了什麼。當你跟蹤這個線路,你可以了解如何修改這種行為,來增加他們下次訪問時購買的可能性。
為了設計最適合你的資料籃子,你可以參考以下三個建議:
1. 尋找一類合適的用戶行為;
2. 測算多少比例的受眾會有這一類的用戶行為;
3. 測試這一類用戶行為是不是包含了重要的信息。
有時候,發明一個新的資料記錄籃子可以促成對公司很大的改變。
舉例
拿Venmo(翻譯君註:一個紐約的小額支付平台)舉個栗子吧。有段時間,公司的支付APP團隊聽說很多本想向朋友索取款項的用戶不慎把錢反而支付給了朋友,因為「索取款項」和「支付款項」的按鈕放在一塊很容易按錯。然而公司並不知道這個問題有多普遍,是否值得公司重新設計用戶界面。為了更好地做決策,他們設計了一個新的資料系統來檢測這個索取/支付失誤有多常見。他們把「A向B付款後不久B雙倍將款項付給了A」這種奇怪的支付行為全都找了出來。結果顯示,這個情況經常發生。所以在下次的產品更新中,他們修復了這個問題。
讓你的資料可分享
阻礙團隊輕鬆分享資料的罪魁禍首常常是資料的定義。因此,從一開始你最好充分完整地定義你的資料。可以考慮建立一個中央辭彙表wiki page, 來讓每個成員更容易理解。Porterfield指出,人們喜歡用奇怪的詞語給資料命名。比如「Ratio」這個詞就常備濫用,因為他們命名時常沒有把分子分母講清楚。
資料是大部分成功公司的生命線。好的資料分享不僅能增加公司的透明度,還能加強不同部門之間的協作。比如在很多公司里,不同部門常常會各自找工程師生成不同資料來回答同一問題。而如果有一個好的分享資料平台這樣的浪費時間精力可以被避免。
另外,讓資料形象化也是一個好平台能輕易做到的。把顆粒資料形象化為圖表可以讓團隊的每一個成員更好地解讀這些資料。對於大部分人來說,理解圖表比理解表格容易得多,因此把資料形象化可以幫助交流更加順暢。
不好的資料分析框架只會打擊人們的自信心。它會無形地把公司分為兩個派別:懂資料的大神以及不懂資料的白痴。這是個很常見的危險錯誤。你必須讓公司最小白的資料用戶都能輕鬆地生成自己需要的圖表並理解它。這是選擇資料平台的一個基本原則。
Poterfield總結道:好的資料分析能讓人們更有準備地去開會,幫銷售團隊問出更到位的問題,免去了無謂的猜測。人們不用再猜測他們的用戶在尋找什麼,或者為什麼他們達成銷售,或者為什麼他們不再回頭。人們也不用再猜測其他團隊的同事知道或者不知道什麼。而這一切都要歸功於從一開始就把資料框架設計好。
4500+企業選擇FineReport報表與 BI 商業智慧工具【免費下載】
opensource開發,類excel設計,全方位異質資料庫整合,資料填報、Flash列印、權限控制、行动應用、客制化、交互分析、報表協同作業管理系統。
分享自:資料觀